It is 2025 and AI is well beyond the experimental phase. It is now embedded in the daily workflows of product teams. Language models assist with drafting OKRs, identifying gaps in strategy, screening interview responses, analyzing churn data and generating test scenarios from acceptance criteria. Most of these tasks are powered by large language models (LLMs).
What Happens During Prompting
When you type a prompt into ChatGPT or Claude, the model replies with something fluent and useful. But what actually happens inside? An LLM is a deep neural network trained on vast amounts of text. It generates responses by predicting one token at a time. This entire process runs on the Transformer architecture, the foundation behind models like GPT-4, Claude and Gemini.
Processing Language with a Transformer
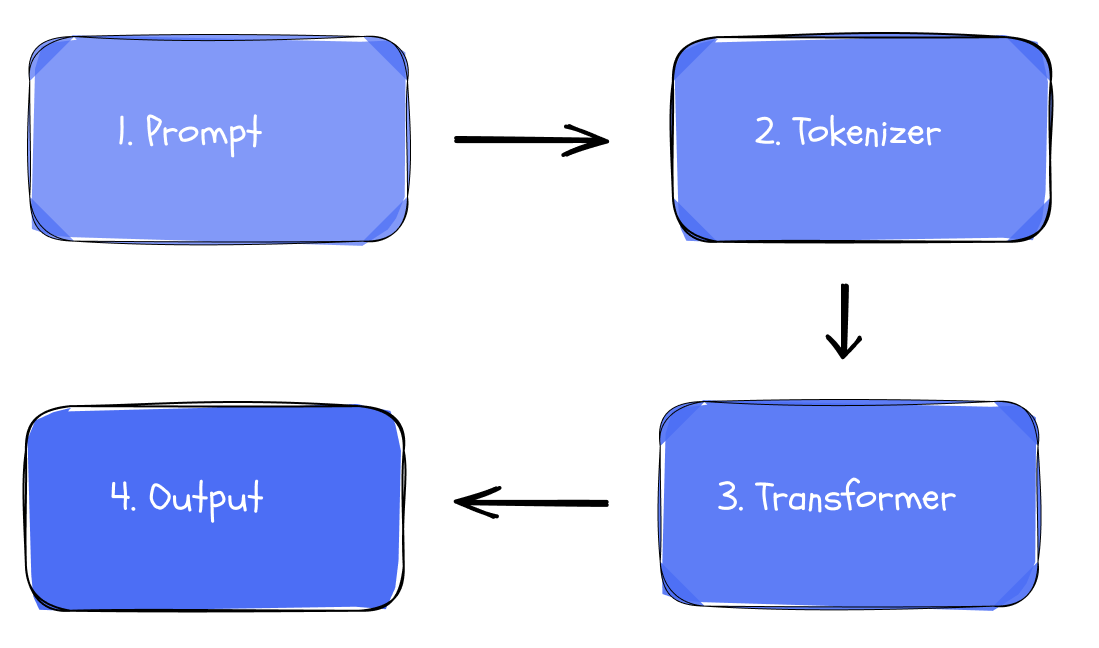
1. Prompt
Everything starts with an input prompt. It defines the task to be completed, such as outlining a product roadmap or generating product ideas. Before processing, the text must be converted into a numerical format.
2. Tokenizer
The first step after the prompt is submitted is tokenization. The input prompt is split into small chunks called tokens. For example, the phrase “machine learning” might become the tokens “machine” and “learning” or even smaller units depending on the model.
Each token is then mapped to a numerical vector known as an embedding. This vector represents the token’s meaning in a form the model can work with.
3. Transformer
This is where the model starts to “think”. Not by understanding, but by comparing.
The input moves through a series of steps where the model figures out how each word relates to the others. It decides what to focus on and what to ignore. This weighing of relevance is called self attention and it is a key part of how the Transformer works. It allows the model to build a sense of meaning based on context.
For example “traffic” means something different next to “landing page” than it does next to “server load”. The model works by spotting statistical patterns it has seen during training and using them to decide what fits best in the current context.
4. Output
After processing the input, the model predicts what comes next. It scores all possible tokens based on everything generated so far, turns those scores into probabilities and selects the most likely next token.
That token is added to the output and the process repeats until the model reaches a limit or completes the response.
LLMs are non deterministic, so the same prompt can produce different outputs. This flexibility is useful, but it makes careful prompting even more important.
Why Model Architecture Matters for Prompting
Context Is Evaluated, Not Understood
Transformer models use self attention to decide which words in the prompt matter most. Since the whole prompt is processed at once, structure becomes important. Key information should appear early and unnecessary repetition should be avoided.
Language Is Predicted, Not Interpreted
Think of LLMs as probability engines that complete text based on patterns, not as humans that understand meaning. LLMs generate output based on learned patterns from training data. They do not understand text but estimate what is likely to follow. Prompts must therefore be precise and well structured.
Intentionally Use Chain-of-Thought Prompting
Encouraging the LLM to reason step by step leads to better answers. This approach reflects chain-of-thought prompting, which aligns well with how the model works.
Final Thoughts
A basic understanding of Transformer architecture is not essential for using LLMs, but it improves both prompting strategy and output.